
الگوریتم GEP در تابع یابی هوشمند
مقدمه
الگوریتم برنامهسازی بیان-ژنی (Gene Expression Programming) روشی برای توسعه برنامههای کامپیوتری و مدلسازی ریاضیاتی بر اساس محاسبات تکاملی و با الهام از تکامل طبیعی است. این روش توسط Ferreira در سال ۱۹۹۹ ابداع و به طور رسمی در سال ۲۰۰۱ معرفی شد (Ferreira, 2001).
الگوریتم GEP در حقیقت نگاه حاکم بر دو الگوریتم وراثتی پیش از خود را در راستای پوشش نقاط ضعف این دو، تجمیع میکند. در این روش، ژنوتایپ کروموزومها مشابه الگوریتم ژنتیک (Genetic Algorithm) یک ساختار خطی دارد و فنوتایپ این کروموزومها به صورت یک ساختار درختی با طول و اندازه متغیر مشابه الگوریتم برنامهسازی ژنتیک (Genetic Programming) است. از این رو الگوریتم GEP با غلبه بر محدودیت نقش دوگانه کروموزومها در الگوریتمهای پیش از خود امکان اعمال عملگرهای متعدد ژنتیک را با ضمانت سلامت همیشگی کروموزومهای فرزند فراهم میسازد و با سرعتی بیش از GP به دلیل تنوع ساختاری بالاتر از GA، فضای پاسخهای ممکن را به صورت کاملتری جستجو میکند. در حقیقت GEP از این منظر موفق به عبور از آستانههای اول و دوم مفروض در فرآیندهای تکامل طبیعی (Replicator Threshhold and Phenotype Threshold) شده است.
متن حاضر درواقع چکیدهای از راهنمای تکمیلی پیوست شده به بسته آموزشی برنامهسازی بیان ژنی است تا پس از مشاهده فیلمهای این بسته، ذهن فراگیران را سازماندهی کند.
ساختار الگوریتم GEP در تابعیابی
فرض کنید میخواهیم رابطه متغیرهای a و b را با متغیر وابسته y کشف کنیم. البته پیش از آن باید در باره وجود ارتباط منطقی میان متغیرها مطالعه نمود. برای مثال آیا استخراج یک رابطه ریاضی میان تعداد اساتید مهندسی معدن کشور استرالیا و تعداد معادن سنگآهن کشور آمریکا حتی اگر دادهها را با دقت مطلوبی توصیف کند، یک مدل منطقی و قابل تعمیم را به دست میدهد؟
به هر روی، ارتباط منطقی میان چند متغیر (در صورت وجود) ممکن است به صورت یک تابع باشد یا دست کم بتوان یک تابع نوشت که با دقت مطلوبی آن را توصیف کند. در این تابع ممکن است عملگرهای جبری (+ – * /)، عملگرهای منطق بولی (مانند OR، AND و IF) و یا انواع توابع جبری مانند مثلثاتی، نمایی، درجه ۲ و ۳ و مانند آنها ایفای نقش کنند. البته در این جا هم امکان حضور این عملگرها و توابع باید با مدل مورد نظر هماهنگ باشد. این مورد در بحث انتخاب توابع در ادامه روشنتر میشود.
چنانچه بخواهیم مسئله کشف مدل توصیفکننده ارتباط متغیرهای a و b با y را با استفاده از الگوریتم GEP حل کنیم، چارچوب اجرای آن به این صورت است که ابتدا یک جمعیت از کروموزومهای خطی (Linear Chromosomes) تشکیل میشود که میتوانند تک-ژنی یا چند-ژنی طراحی شده باشند.
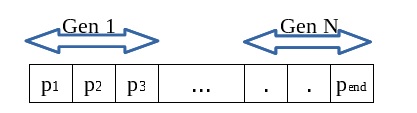
شکل ۱. نمونهای از یک کروموزوم نمادین با تعداد N ژن به طول ۳
در هر موقعیت (Position) از ژنهای این کروموزومها ممکن است یکی از متغیرها (در این جا a و b و y که پیش از این هم به الگوریتم اعلام شده که کدام مستقل و کدام وابسته است) یا یکی از توابع/عملگرهایی که ما حدس زدهایم و در نظر گرفتهایم، قرار گیرد.
بعد از ایجاد کروموزومها و پر کردن جایگاههای آنها نوبت آن میرسد که برازندگی هر فرد (کروموزوم) در نسل مورد بررسی، سنجیده شود. بدین منظور، در الگوریتم GEP کروموزمها به صورت (Expression Tree) یا همان ET بیان میشوند. یک ET مشابه یک پروتئین در سلول طبیعی تعیین میکند که برونداد (Phenotype) یک ژن چیست.
Ferreira یک زبان ساده و کارآمد به نام Karva برای بیان ژنها و ایجاد ETها ابداع کرده است که بر اساس آن از هر کروموزوم متشکل از terminalها و functionهای تصادفی، یک معادله ریاضی (یک برنامه) ایجاد و استخراج میشود. حالا اگر یک دسته داده آزمون (Fitness Case) به عنوان نمونه در اختیار باشد (منظور یک مجموعه از نقاط است که در هر نقطه مقدار y به ازای مقادیر a و b برداشت و ثبت شده باشد) میتوان ارزیابی کرد که مقدار y حاصل از این معادله به ازای مقادیر مشخص a و b در نقاط مختلف تا چه حد به مقدار y واقعی همان نقاط نزدیک است. این اختلاف هر چه کمتر باشد، گواه دقت بیشتر این معادله و در نتیجه برازندگی بالاتر این کروموزوم است.
در مورد هر یک از کروموزومهای تولید شده در نسل اول مقدار برازندگی به این شیوه محاسبه میشود و این کروموزومها بسته به نسبت مقدار برازندگیشان به برازندگی کل، یک امتیاز برای حضور در نسل بعد میگیرند. در ضمن، برازندهترین فرد در هر نسل بدون فرآیند انتخاب به صورت مستقیم به نسل بعد منتقل (Clone) میشود.
برای ایجاد نسل بعد از حالت خطی (ژنوتایپ) کروموزومها استفاده میشود. به این ترتیب تمام طول کروموزوم خواه فعال و خواه غیرفعال در تولید نسل بعد حضور خواهد داشت. چه بسا که بخش غیرفعال یک ژن با یک جهش در نسل بعد به یک بخش فعال و کاملا برازنده تبدیل شود.
نخستین گام در تولید نسل بعد فرآیند همانندسازی (Replication) است که در اینجا برای تحقق آن از روش چرخگردان (Roulette Wheel) استفاده میشود. چرخ گردان میچرخد (البته به لحاظ مفهومی این چنین است) و هر بار یک کروموزوم را انتخاب میکند (این انتخاب در اصل با تولید و تخصیص اعداد تصادفی کدنویسی میشود). کروموزومهای با امتیاز بالاتر بخت فزونتری برای انتخاب دارند اگر چه هیچ تصمینی وجود ندارد و درست همین ویژگی، الگوریتم را به فرآیند انتخاب تصادفی طبیعت نزدیک میکند. اجرای این فرآیند تا جایی ادامه مییابد که به تعداد نسل جاری، کروموزوم به نسل بعد منتقل شود تا تعداد کروموزومها (در این جا ۱۰۰ کروموزوم) همواره در طول تکامل ثابت باشد؛ سپس عملیات بازپردازی (Restructuring) آغاز میشـود. بدین معنی که عملگرهای ژنتیکی به ترتیبی که در الگوریتم معین شده است بر کروموزومهای همانندسازی شده وارد میشوند تا کروموزومها دچار تغییر شوند. این که عملگرها بر چند درصد از کروموزمها عمل میکنند و نحوه عمل آنها در کروموزومها به صورت منفرد چگونه است را باید با تنظیم نرخ هر یک از عملگرها تعیین نمود. برای نمونه اگر نرخ عملگر جهش (Mutation Rate) برابر با ۰/۰۳۳ در نظر گرفته شود، این بدان معنی است که تعداد نقاط جهشیافته در هر کروموزوم معادل همین نسبت از طول آن است. چنان که اگر طول کروموزم برای مثال شامل سه ژن ۲۰ واحدی، معادل ۶۰ واحد باشد، اعمال نرخ جهش بالا، به معنای جهش ۲ نقطه (۶۰ * ۰/۰۳۳) در طول کروموزوم در فرآیند انتقال آن به نسل بعد است.
روند بالا برای ایجاد کروموزومهای نسل جدید و آزمون پیدرپی آنها به تدریج موجب شبیهسازی تکامل طبیعی شده و اغلب پس از تعداد نسـل معینی به معادلـه بهیـنـه با دقت مورد نظر نزدیک میشود. البته برای تعداد تکرارهای الگوریتم هم میتوان محدودهای تعیین نمود تا در صورتی که پس از مدت معینی بهبودی در الگوریتم حاصل نشد از هدررفت حافظه و زمان جلوگیری شود.
مراحل طراحی و اجرای الگوریتم GEP در تابعیابی
تا اینجا با ساختار اجرای الگوریتم GEP آشنا شدید. برای جمعبندی پنج گام اصلی طراحی آن را به خاطر بسپارید:
۱- تعریف تابع برازندگی؛
۲- تعریف terminalها و functionها؛
۳- تعیین ساختار کروموزومها (تعداد در نسل، طول ژنها و تعداد آنها)؛
۴- تعیین تابع اتصال ژنها (Linking Function)؛
۵- تعیین مشخصات عملگرها و در نهایت اجرای الگوریتم.
الگوریتم اجرایی GEP بر اساس نظر Ferreira در شکل 2 آورده شده است.
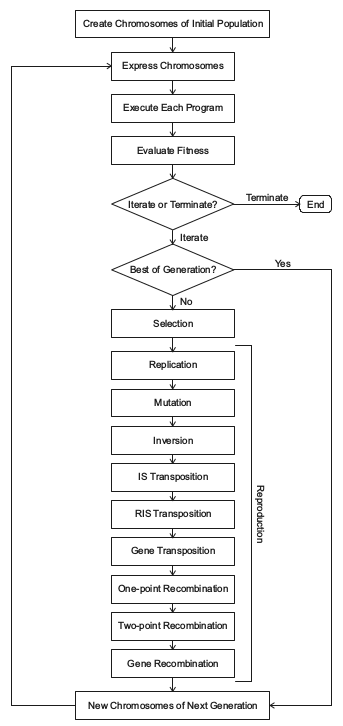
شکل 2. الگوریتم پایه GEP
فهرست منابع
آصفی، م. برنامهسازی بیان-ژنی (مدلسازی ریاضی با هوش مصنوعی). وبسایت علمی-آموزشی زمینو. 1396.
Ferreira, C. (2001), “Gene expression programming: A new adaptive algorithm for solving problems,” Complex Systems, 13 (2): 87-129.
درباره نویسنده

مصطفی آصفی از بنیانگذاران مجموعههای آموزشی زمینو و همرویش مستقر در پارک علم و فناوری استان همدان است…+







دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.